ChatGPT
BotHub
24 октября 2025 г.
Ограничение контекстного окна GPT-5 и его эффективное использование в Bothub
Доброго времени суток!В сегодняшней статье мы разберемся в ограничениях контекстного окна GPT-5, рассмотрим его применение относительно Bothub и ответим на вопрос: как повысить эффективность?Присаживайтесь поудобнее, я начинаю свое повествование.

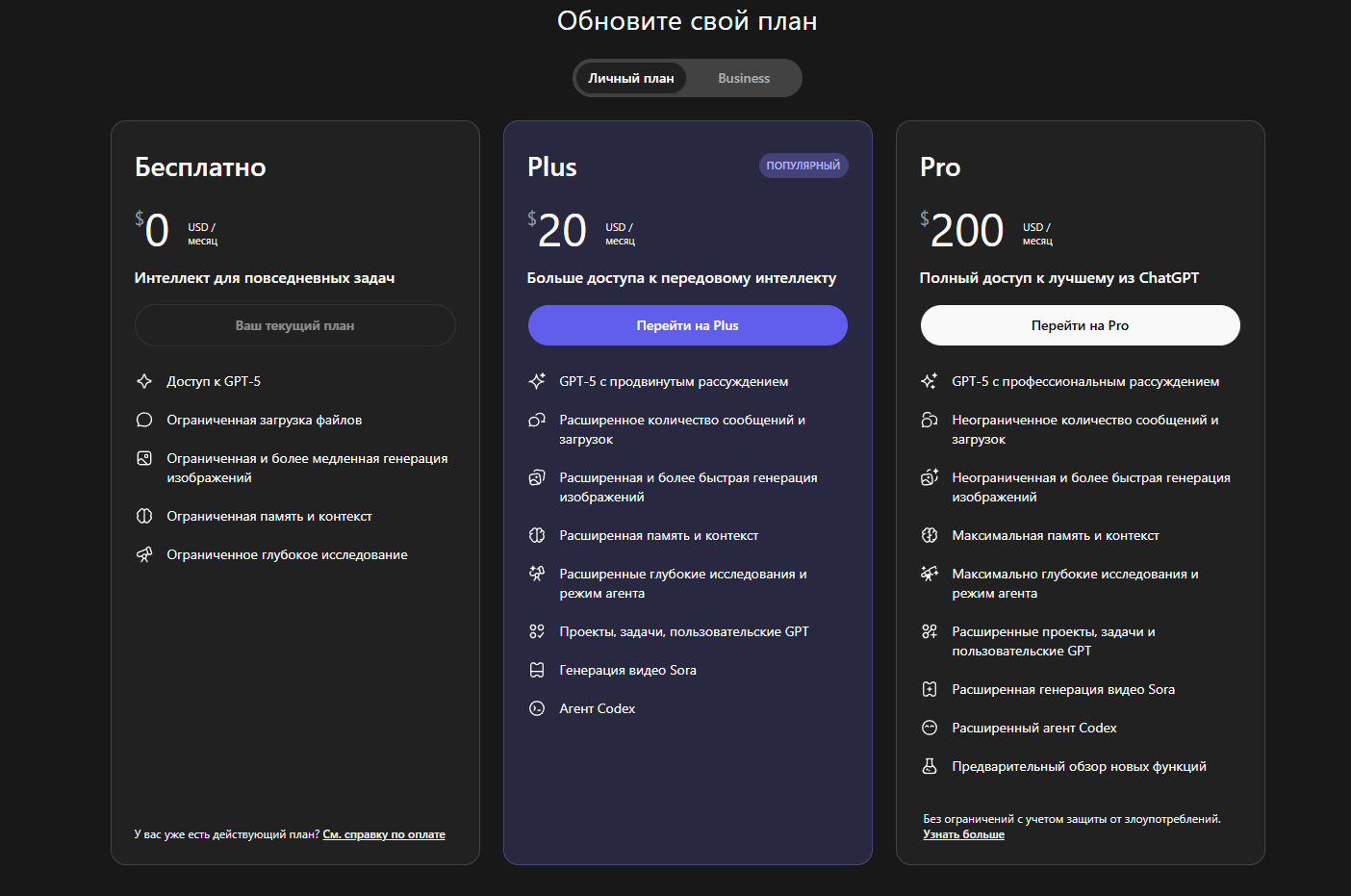
Контекстное окно устанавливает верхний предел объема данных, которые модель способна обработать за один запрос или диалог. Оно измеряется в токенах — кусочках информации, на которые модель дробит наш текст. Этот параметр определяет возможности работы с крупными документами, сохранения истории разговора и выполнения многоэтапных задач.На официальном сайте OpenAI выбор определенного тарифа непосредственно влияет на ограничения контекстного окна:
- Бесплатный тариф — 16 000 токенов.
- Уровень Plus и Business — 32 000 токенов за за запрос.
- Тарифы Pro и Enterprise — 128 000 токенов за запрос.
- API поддерживает обработку до 400 000 токенов за запрос, однако данная опция недоступна через интерфейс.
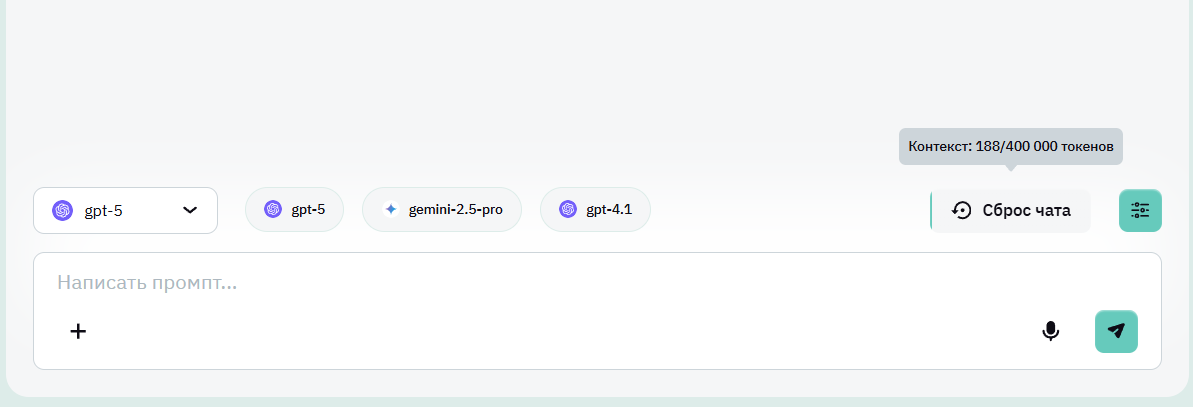
Здесь же рассмотрим специфику GPT-5 на платформе Bothub. Всё гораздо проще и сложнее одновременно. В отличие от OpenAI, здесь приобретаются не тарифы, а «капсы» (внутренняя валюта), расходуемые при запросах к различным моделям (например, средний запрос для GPT-5 тратит около 20 000 капсов). По специальной ссылке для регистрации можно получить 100 000 капсов для личных целей.Сам GPT-5 на Bothub предоставляется через API и способен принимать запросы длиной до 400 000 токенов.. Если быть более точным, то в это число токенов входит 128 000 токенов генерируемого ответа, а также 272 000 на сам запрос.При работе на Bothub вы можете посмотреть насколько заполнен ваш контекст в настоящем времени. Достаточно полезная функция, которая поможет контролировать этот момент во избежания проблем с ним.
Оптимизация обработки больших документов в рамках контекста
Если вы работаете с большими документами или ведете достаточно продолжительный диалог, который превышает предел контекстного окна, можно заметить, что GPT-5 начинает терять связь с предыдущими ответами.Проблема актуальна как для официальной версии модели, так и для версий на Bothub. И вообще не только GPT-5 сталкивается с такой ситуацией. Рассмотрим способы оптимизации работы с длинным контекстом:- Разбейте нужный документ на более короткие, логически связанные разделы. Это поможет получить конкретные ответы на каждую часть и избавит от лишней нагрузки на ограниченный объем контекста (для пользователей тарифа Plus текст из 100 страниц нужно будет разбить на 4 равных фрагмента для эффективной работы модели). То же самое касается и суммаризации больших текстов. Разделите их на разделы, выполните суммаризацию каждого раздела отдельно, после чего получите общий итоговый ответ уже на основе суммаризированных частей. Вообще для суммаризации существует множество внутренних методов обработки. Например, фрагментарная обработка в ChatGPT — последовательный перебор частей текста с частичным захватом предыдущего фрагмента, чтобы избежать потери данных. Модель также может нормализовать текст (сводить слова к корневым формам), извлекать ключевые фразы, предложения и абзацы, что позволяет сократить число занятых токенов.
- Обобщайте ранее полученный контент и кратко описывайте контекст в каждом следующем запросе. Так снижается риск утраты важной информации моделью.
- Сохраняйте промежуточные результаты, например, в текстовых документах. Это позволит не потерять ход мыслей и избежать повторного прохождения всех этапов с самого начала.
- Работая через API, внимательно следите за структурой запросов, чтобы уложиться в ограничение по количеству токенов (не более 400 000).
- Переводите необходимые документы с русского на английский. Английский текст содержит примерно в четыре‑шесть раз меньше токенов, чем аналогичный русский текст, так как тот сложен морфологически, да и роль играют некоторые особенности работы токенизатора ChatGPT.
- Грамотно составить промт под вашу задачу без каких‑либо дополнительных нагромождений. Понять, как это делается, можно с помощью других статей на эту тему.
- Использование функций на базе технологии RAG. Сервисы на его основе (например, «Проекты» в ChatGPT) сначала индексируют все данные, а затем для ответа подтягивают только релевантные фрагменты. В своей сути это позволяет в какой‑то степени обходить ограничения контекстного окна.