BotHub
Очередь промтов
25 октября 2025 г.
Очередь промтов: автоматизируем работу нейросетей c BotHub
Привет! Вспомните, как часто вы сталкивались с тем, что даже самая продвинутая нейросеть выдавала вам странный, неполный или попросту не тот результат? Вы составили подробный промт, тщательно прописали все условия, а на выходе получили нечто совершенно не соответствующее вашим ожиданиям. Мы все были там. На данном этапе нужно понимать, что проблема не в ИИ, а в нашем подходе.Мы пытаемся вскинуть на него монолитное условие задачи, ожидая, что он аккуратно её раздробит. Но правильный путь — дробить задачу самим, используя очередь промтов. Эта функция используется в агрегаторе нейросетей Bothub. Его мы будем использовать для работы над проектом. К тому же, при регистрации по этой ссылке – мы получим 100 тысяч капсов генерации. Этого с запасом хватит для нашего исследования.Давайте разбираться, как превратить диалог с нейросетью из угадайки — в предсказуемый конвейер по производству качественных решений.

Основные принципы очереди промтов
Сложную задачу — будь то диалог с ИИ или создание приложения — нужно дробить на последовательные шаги. Этот принцип цепочки промтов лежит в основе эффективной работы с любым агрегатором нейросетей. Мы рассмотрим эту технологию на примере Bothub. Это мощный конструктор, но именно ваши промты являются инструкциями для сборки. Рассмотрим несколько ключевых принципов, которые позволят вам выжать из него максимум, превратив хаотичный запрос в предсказуемый и качественный результат.Контекст
Агрегатор позволяет вести продолжительные диалоги, где каждая следующая реплика учитывает предыдущие. Вместо того чтобы каждый раз начинать с чистого листа с огромным промтом в духе «Ты умный студент, напиши...», мы создадим контекст один раз. Нейросеть сохраняет контекст диалога, но мои тесты показали — установка роли в первом промте повышает согласованность следующих ответов. Вместо разового гигантского ТЗ, пишем следующим образом:Промт 1 (устанавливаем контекст): «Анализируй задачи как senior data scientist. Отвечай структурированно, с примерами на Python. Избегай водных вступлений.»Промт 2 (задача): «Сгенерируй код для A/B-теста с поправкой на множественные сравнения. Используй библиотеку statsmodels.»Декомпозиция
Сложные запросы дают нерелевантные результаты. Разбивка на этапы решает эту проблему:Этап 1: «Проанализируй датасет с метриками retention. Какие 3 гипотезы о сегментах пользователей можно выдвинуть?»Этап 2: «Для гипотезы №2 предложи метод статистической проверки и напиши код для её тестирования»Принцип работы К сожалению, многослойный промт вроде «Проанализируй датасет, выяви аномалии, предложи методы их обработки, напиши код и визуализируй результат» перегружает контекстное окно модели. Каждый последующий элемент запроса забывает предыдущий, что приводит к поверхностным ответам.Мы разбиваем задачу на логические этапы, где каждый следующий шаг использует результат предыдущего. Например:Анализ данных: «Определи типы данных в каждом столбце датасета и выяви пропущенные значения».Постановка гипотез: «На основе результатов предложи 2-3 гипотезы о природе аномалий в данных».Верификация: «Для гипотезы №1 предложи статистический метод проверки и обоснуй его применимость».Такой подход снижает когнитивную нагрузку на модель; ИИ фокусируется на одной подзадаче не забивая память десятками условий. В то же время мы, как пользователь, можем корректировать направление решения, не перезапуская весь процесс.Пример: Вместо запроса «Напиши ML-модель для предсказания оттока клиентов» лучше последовательно уточнять:«Какие признаки в данных наиболее коррелируют с оттоком?»«Какой метод классификации подойдет для несбалансированных данных?»«Напиши код для логистической регрессии с учетом дисбаланса классов».Таким образом, декомпозиция превращает работу с ИИ из черного ящика в прозрачный итеративный процесс.Структурирование ввода по шаблонам
Ключевая проблема сложных запросов — отсутствие четкого разделения между исходными данными, задачей и требованиями к формату ответа. Когда все элементы перемешаны в одном тексте, нейросеть должна догадываться, что именно является наиболее важным. Структурирование решает эту проблему через визуальное и логическое разделение компонентов запроса.Используем четкие разделители и форматирование, чтобы создать "каркас" для промта. Например:ДАННЫЕ: «[здесь размещаем ваш текст, датасет или исходную информацию]» ЗАДАЧА: 1. Проанализируй основные тенденции в данных 2. Выдели 2-3 ключевых инсайта 3. Предложи рекомендации для дальнейшего исследования ФОРМАТ ОТВЕТА: - Анализ: [краткое описание] - Инсайты: [нумерованный список] - Рекомендации: [тезисно]Благодаря такому подходу нейросеть лучше понимает, где исходные данные, а где сама задача и как должен выглядеть результат. А ещё подобный шаблон можно использовать многократно, подкручивая его под разные задачи.Пример: Вместо "Проанализируй этот отзыв и скажи, что улучшить" используем:ТЕКСТ ОТЗЫВА: «Отличный функционал, но интерфейс сложный. Иногда зависает при загрузке больших файлов.» ЗАДАЧА: 1. Классифицируй отзыв по тональности (позитивный/негативный/смешанный) 2. Выдели основные проблемы 3. Предложи приоритеты для исправления ФОРМАТ: - Тональность: [оценка] - Проблемы: [список] - Приоритеты: [ранжированный список]Верификация результатов
Каждый четвертый ответ ИИ содержит неточности в коде или аргументации. Финал цепочки промтов — всегда проверка:«Проверь предложенное решение на соответствие PEP8 и наличие edge cases. Для датасета с пропусками в 5% данных — будет ли метод корректен?»Итеративное уточнение: шлифовка ответа до идеала
Итеративное уточнение построено на цикле «запрос → оценка → коррекция», где каждый следующий промт приближает результат к желаемому. Это живой диалог, а не однократный запрос.Исходный запрос: «Проанализируй данные по продажам» Ответ ИИ: предоставляет общую статистику Уточнение 1: «Добавь сравнение с предыдущим кварталом» Уточнение 2: «Выдели сегмент B2B-клиентов отдельно» Уточнение 3: «Предложи 3 гипотезы падения продаж в сегменте B2B»Таким образом, каждое уточнение сужает поле поиска решений, и мы последовательно избавляемся от неточностей. Вместо того чтобы начинать с нуля после неудачного промта, мы шлифуем его.Нейросеть для анализа лунных снимков
Итак, мы разобрали теорию очереди промтов. Теперь давайте соберем все воедино и создадим работающую нейросеть для классификации лунных объектов.Регистрируемся на официальном сайте Bothub.Видим перед собой домашнюю страничку.
Выбираем модель gpt 4.1 – nano. Справа от диалогового окна, нажимаем на интересующую нас функцию — очередь промтов.
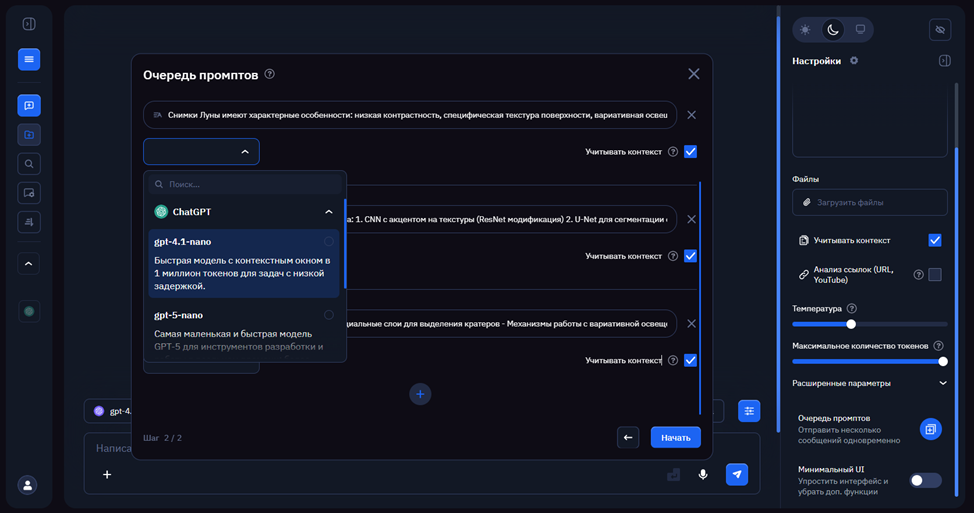
Обязательно проставляем галочки в полях «Учитывать контекст». Благодаря этому, нейросеть будет учитывать историю диалога промтов.Давайте составим их, в соответствии с принципами, о которых мы говорили в начале статьи.[1/4]
На основе требований к архитектуре создай код препроцессинга для лунных снимков. Включи:
1. Аугментацию данных: - Random rotation (±15°) - Adjust brightness/contrast (вариация 20%) - Gaussian noise (σ=0.01) - Mirroring (вертикальное/горизонтальное)
2. Предобработку: - Normalization (0-1) - High-pass фильтр для выделения кратеров - Multi-scale processing (256x256, 512x512)
3. Функции загрузки данных: - PyTorch DataLoader - Support for different image formats - Batch processing with memory optimization Сгенерируй готовый код на PyTorch с комментариями на русском.
[2/4]
Реализуй архитектуру Hybrid CNN-Transformer для классификации лунных объектов:
1. ResNet50 backbone (первые 3 слоя заморожены)
2. Vision Transformer блоки (4 слоя, dim=512)
3. ASPP модуль (rates=[6, 12, 18])
4. Attention механизмы в skip-connections Добавь: - Инициализацию весов (He normal) - Dropout (0.3) - BatchNorm с learnable parameters Код должен быть готов к обучению на GPU.
[3/4]
Напиши код для обучения модели:
1. Loss function: Focal Loss (γ=2.0)
2. Optimizer: AdamW (lr=1e-4, weight_decay=1e-5)
3. Scheduler: CosineAnnealingLR (T_max=10) 4. Metrics: Precision, Recall, F1-score 5. Early stopping (patience=7) Добавь логирование и визуализацию прогресса.
[4/4]
Проанализируй созданный код и предложи оптимизации:
1. Ускорение DataLoader (подсказка: pinned memory, prefetch)
2. Добавление mixed precision training
3. Оптимизация памяти для больших изображений
Наши промты соответствуют вышеупомянутым принципам; большая задача дробится на подзадачи, запросы выстроены по единому шаблону, в каждом новом промте уточняем предыдущие вопросы.Посмотрим на результаты.import os
import argparse
import torch
from typing import Optional
from preprocessing import create_train_val_dataloaders, get_image_paths
from model import create_model
from training import train_model, load_model
from utils import (set_seed, print_system_info, create_directory_structure,
create_sample_data, save_config, load_config, get_device_info)
def parse_arguments():
"""Парсинг аргументов командной строки"""
parser = argparse.ArgumentParser(description='Обучение модели анализа лунных снимков')
# Пути к данным
parser.add_argument('--data_dir', type=str, default='lunar_images',
help='Путь к директории с изображениями')
parser.add_argument('--save_dir', type=str, default='checkpoints',
help='Директория для сохранения модели')
# Параметры модели
parser.add_argument('--model_type', type=str, default='hybrid',
choices=['hybrid', 'simple'],
help='Тип модели')
parser.add_argument('--num_classes', type=int, default=5,
help='Количество классов')
parser.add_argument('--dropout', type=float, default=0.3,
help='Dropout probability')
parser.add_argument('--pretrained', action='store_true', default=True,
help='Использовать предобученные веса')
# Параметры обучения
parser.add_argument('--epochs', type=int, default=50,
help='Количество эпох')
parser.add_argument('--batch_size', type=int, default=8,
help='Размер батча')
parser.add_argument('--lr', type=float, default=1e-4,
help='Learning rate')
parser.add_argument('--weight_decay', type=float, default=1e-5,
help='Weight decay')
parser.add_argument('--gamma', type=float, default=2.0,
help='Gamma для Focal Loss')
parser.add_argument('--patience', type=int, default=7,
help='Patience для early stopping')
# Параметры данных
parser.add_argument('--val_split', type=float, default=0.2,
help='Доля данных для валидации')
parser.add_argument('--num_workers', type=int, default=4,
help='Количество воркеров для DataLoader')
parser.add_argument('--create_sample_data', action='store_true',
help='Создать примерные данные для тестирования')
# Другие параметры
parser.add_argument('--seed', type=int, default=42,
help='Seed для воспроизводимости')
parser.add_argument('--resume', type=str, default=None,
help='Путь к checkpoint для возобновления обучения')
parser.add_argument('--config', type=str, default=None,
help='Путь к файлу конфигурации')
return parser.parse_args()
def create_default_config(args) -> dict:
"""Создание конфигурации по умолчанию"""
config = {
'data': {
'data_dir': args.data_dir,
'val_split': args.val_split,
'batch_size': args.batch_size,
'num_workers': args.num_workers
},
'model': {
'type': args.model_type,
'num_classes': args.num_classes,
'dropout': args.dropout,
'pretrained': args.pretrained
},
'training': {
'epochs': args.epochs,
'lr': args.lr,
'weight_decay': args.weight_decay,
'gamma': args.gamma,
'patience': args.patience
},
'system': {
'seed': args.seed,
'device': 'cuda' if torch.cuda.is_available() else 'cpu'
}
}
return config
def main():
"""Основная функция"""
args = parse_arguments()
# Установка seed
set_seed(args.seed)
# Вывод информации о системе
print_system_info()
# Создание структуры директорий
create_directory_structure()
# Создание директории для сохранения
os.makedirs(args.save_dir, exist_ok=True)
# Загрузка конфигурации если указана
if args.config and os.path.exists(args.config):
config = load_config(args.config)
print(f"Загружена конфигурация из {args.config}")
else:
config = create_default_config(args)
# Сохранение конфигурации
config_path = os.path.join(args.save_dir, 'config.json')
save_config(config, config_path)
print(f"Сохранена конфигурация в {config_path}")
# Создание примерных данных если нужно
if args.create_sample_data:
print("Создание примерных данных...")
sample_dir = create_sample_data("sample_lunar_data", num_samples=200)
args.data_dir = sample_dir
print(f"Созданы примерные данные в {sample_dir}")
# Проверка наличия данных
if not os.path.exists(args.data_dir):
print(f"Директория {args.data_dir} не существует!")
print("Используйте --create_sample_data для создания примерных данных")
return
# Получение путей к изображениям
image_paths = get_image_paths(args.data_dir)
if len(image_paths) == 0:
print(f"Не найдено изображений в директории {args.data_dir}")
return
print(f"Найдено {len(image_paths)} изображений")
# Создание модели
print(f"Создание модели типа: {args.model_type}")
model = create_model(
model_type=args.model_type,
num_classes=args.num_classes,
dropout_prob=args.dropout,
pretrained=args.pretrained
)
# Вывод информации о модели
print(f"Количество параметров: {sum(p.numel() for p in model.parameters()):,}")
# Создание DataLoader'ов
print("Создание DataLoader'ов...")
train_loader, val_loader = create_train_val_dataloaders(
image_dir=args.data_dir,
val_split=args.val_split,
batch_size=args.batch_size,
num_workers=args.num_workers
)
if train_loader is None or val_loader is None:
print("Ошибка создания DataLoader'ов!")
return
print(f"Обучающих батчей: {len(train_loader)}")
print(f"Валидационных батчей: {len(val_loader)}")
# Загрузка checkpoint если указан
if args.resume and os.path.exists(args.resume):
print(f"Загрузка checkpoint из {args.resume}")
checkpoint = load_model(model, args.resume, torch.device(config['system']['device']))
print(f"Загружен checkpoint с F1-score: {checkpoint.get('best_f1', 'N/A')}")
# Обучение модели
print("Начало обучения...")
results = train_model(
model=model,
train_loader=train_loader,
val_loader=val_loader,
num_epochs=args.epochs,
learning_rate=args.lr,
weight_decay=args.weight_decay,
gamma=args.gamma,
patience=args.patience,
save_dir=args.save_dir
)
print("Обучение завершено!")
print(f"Лучший F1-score: {results['best_f1']:.4f}")
print(f"Время обучения: {results['total_time']:.2f} секунд")
# Сохранение результатов
results_path = os.path.join(args.save_dir, 'results.json')
save_config(results, results_path)
print(f"Результаты сохранены в {results_path}")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("\nОбучение прервано пользователем")
except Exception as e:
print(f"Ошибка: {e}")
import traceback
traceback.print_exc()
Анализ результатов
Давайте разберём каждый блок кода.Естественно, сначала идут импорты и зависимости. Torch - основной фреймворк для нейросетей, argparse - для обработки аргументов командной строки.Модули preprocessing, model, training, utils - кастомные модули нашей системы, typing.Optional – для лучшей читаемости.import os import argparse import torch from typing import Optional from preprocessing import create_train_val_dataloaders, get_image_paths from model import create_model from training import train_model, load_model from utils import (set_seed, print_system_info, create_directory_structure, create_sample_data, save_config, load_config, get_device_info) Далее мы создаём интерфейс для запуска кода с разными параметрами, и конфигурацию по умолчанию.Функция create_default_config берет сырые аргументы из командной строки и организует их в логические группы. Например, в раздел 'data' попадают все параметры, связанные с обработкой данных; путь к изображениям, как их разделять на тренировочные и валидационные наборы, как загружать батчи.В раздел 'model' группируются параметры архитектуры нейросети: какой тип модели использовать, сколько классов распознавать, какие методы регуляризации применять. В раздел 'training' собираются настройки процесса обучения: сколько эпох тренировать, с каким learning rate, как настроить функцию потерь и когда останавливать обучениеВ раздел 'system' помещаются технические параметры: seed для воспроизводимости результатов и автоматическое определение доступного устройства (проверка torch.cuda.is_available() определяет, есть ли GPU)Тип возврата -> dict указывает, что функция возвращает словарь, что помогает редактору кода предлагать автодополнение при работе с конфигурацией в других частях программы.Также аргументы подразделяются на несколько групп:Пути: --data_dir, --save_dirМодель: --model_type, --num_classes, --dropoutОбучение: --epochs, --batch_size, --lrДанные: --val_split, --num_workersУтилиты: --seed, --resume, --configФункция main()
def main(): """Функция main координирует весь процесс обучения от начала до конца""" # Парсинг аргументов командной строки args = parse_arguments() # Установка seed обеспечивает воспроизводимость результатов set_seed(args.seed) # Вывод информации о системе помогает диагностировать проблемы print_system_info() # Создание директорий для чекпоинтов и логов create_directory_structure() # Создание директории сохранения модели os.makedirs(args.save_dir, exist_ok=True) args = parse_arguments() - функция считывает параметры, которые пользователь указал в командной строке, и сохраняет их в объект argsset_seed(args.seed) - устанавливает seed 42 для генераторов случайных чисел в PyTorch, NumPy и Python, что гарантирует одинаковые результаты при повторных запускахprint_system_info() - выводит детальную информацию о системе: версию PyTorch, наличие CUDA, объем памяти GPU, что помогает понять, на каком оборудовании происходит обучениеcreate_directory_structure() - создает необходимые папки checkpoints/, logs/, results/ если они не существуютos.makedirs(args.save_dir, exist_ok=True) - создает указанную пользователем директорию для сохранения чекпоинтов моделиСоздание модели
print(f"Создание модели типа: {args.model_type}") model = create_model( model_type=args.model_type, num_classes=args.num_classes, dropout_prob=args.dropout, pretrained=args.pretrained ) # Вывод информации о модели print(f"Количество параметров: {sum(p.numel() for p in model.parameters()):,}") model = create_model(...) - функция create_model создает экземпляр нейронной сети на основе указанных параметров:- model_type=args.model_type - определяет архитектуру ('hybrid' или 'simple')
- num_classes=args.num_classes - устанавливает количество выходных классов (5 для лунных объектов)
- dropout_prob=args.dropout - настраивает вероятность dropout 0.3 для борьбы с переобучением
- pretrained=args.pretrained - загружает предобученные веса ImageNet если установлено True
- sum(p.numel() for p in model.parameters()) - вычисляет общее количество обучаемых параметров модели:
- p.numel() - возвращает количество элементов в каждом параметре
- sum(...) - суммирует все параметры всех слоев
Подготовка DataLoader’ов
create_train_val_dataloaders(...) - функция выполняет несколько задач:- Загружает все изображения из указанной директории
- Разделяет данные на тренировочную и валидационную части согласно val_split=0.2
- Применяет аугментации к тренировочным данным (повороты, изменение яркости)
- Создает DataLoader'ы с указанным размером батча batch_size=8
- if train_loader is None or val_loader is None: - проверяет, что DataLoader'ы были созданы успешно, и если возникла ошибка - останавливает программу
Запуск обучения
# Обучение модели print("Начало обучения...") results = train_model( model=model, train_loader=train_loader, val_loader=val_loader, num_epochs=args.epochs, learning_rate=args.lr, weight_decay=args.weight_decay, gamma=args.gamma, patience=args.patience, save_dir=args.save_dir ) Конкретные действия функции train_model:Подготовка оптимизатора - создаёт оптимизатор AdamW с learning rate 0.0001 и weight decay 0.00001 для регуляризацииДалее мы инициализируем планировщик CosineAnnealingLR, который плавно уменьшает learning rate по косинусоидальному закону каждые 10 эпох.Инициализация функции потерь - создаёт Focal Loss с gamma=2.0, который уделяет больше внимания сложным для классификации примерамЦикл обучения - для каждой эпохи от 1 до 50:Переключает модель в режим тренировки model.train()Проходит по всем батчам тренировочных данныхВычисляет градиенты и обновляет веса моделиПереключает модель в режим оценки model.eval()Проверяет качество на валидационных данныхРанняя остановка - отслеживает метрики и останавливает обучение, если качество не улучшается 7 эпох подрядСохранение чекпоинтов - сохраняет лучшую версию модели в директорию save_dirФинал
print("Обучение завершено!") print(f"Лучший F1-score: {results['best_f1']:.4f}") print(f"Время обучения: {results['total_time']:.2f} секунд") # Сохранение результатов results_path = os.path.join(args.save_dir, 'results.json') save_config(results, results_path) print(f"Результаты сохранены в {results_path}") Вывод итоговых метрик:results['best_f1'] - показывает лучшее достигнутое значение F1-score с точностью до 4 знаковresults['total_time'] - отображает общее время обучения в секундах с точностью до 2 знаковСохранение результатов:os.path.join(args.save_dir, 'results.json') - создаёт полный путь к файлу результатов, объединяя директорию сохранения с именем файлаsave_config(results, results_path) - записывает все метрики обучения в JSON-файл.Графики
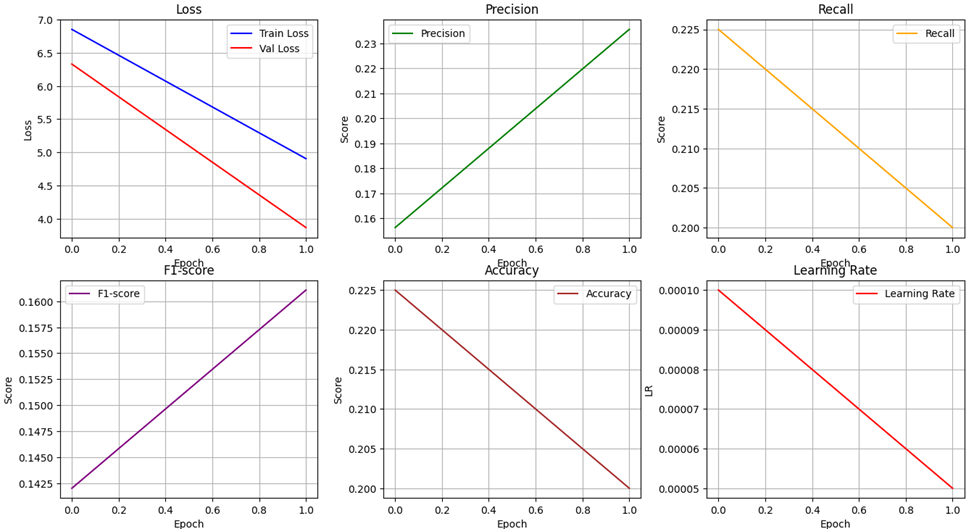
Давайте проанализируем каждый график:Обучение модели (Loss):Как видно, как обучение, так и валидация показывают устойчивое снижение потерь с увеличением количества эпох.Потери на обучении и валидации сходятся к низким значениям, что указывает на хорошую сходимость модели без признаков переобучения.Точность (Accuracy):Точность модели немного снижается при увеличении эпох, что необычно, так как обычно точность должна расти. Возможно, это связано с небольшими колебаниями или шумом в данных, или с тем, что модель не сильно переобучилась и достигла своего оптимума.Показатели Precision и Recall:Precision растет с эпохами, достигая примерно 0.23, что говорит о постепенном улучшении точности положительных предсказаний.Recall снижается чуть-чуть, достигая около 0.22, что указывает на снижение способности модели обнаруживать все положительные случаи.В целом, эти показатели близки друг к другу, что говорит о сбалансированной работе модели.F1-score:Значение F1-score увеличивается с эпох, достигая примерно 0.16.Значит, баланс между Precision и Recall улучшается, хотя показатели все еще остаются относительно низкими.Learning Rate:Learning Rate снижается с эпохами, что типично для методов обучения с адаптивным снижением скорости обучения для улучшения сходимости.Общий вывод:В целом, модель хорошо обучается, потери снижаются, и показатели Precision, Recall и F1-score улучшаются.Однако показатели по-прежнему остаются низкими, что может свидетельствовать о сложности задачи или необходимости дальнейшей настройки модели. Но, важно понимать, что данную модель мы создали с нуля и не написали ни одну строку кода.